现在非常多网站(尤其是众多AI模型辅助生成得网站如最近热火的lovable)基于React、Vue、Angular 带来的动态交互体验备受青睐,但随之而来的 JS SEO 问题却让SEOer头疼——谷歌爬虫“看不懂”客户端渲染(CSR)的动态内容,导致页面收录率骤降;即便是服务端渲染(SSR),也可能因 hydration 不匹配、缓存策略不当踩坑。更关键的是,谷歌近期针对 JS 付费墙的更新,进一步明确了动态内容的合规要求。一起结合谷歌官方文档与实战经验,拆解各框架的SEO痛点,给出可落地的解决方案。
一、先搞懂:JS 框架的 SEO 核心痛点
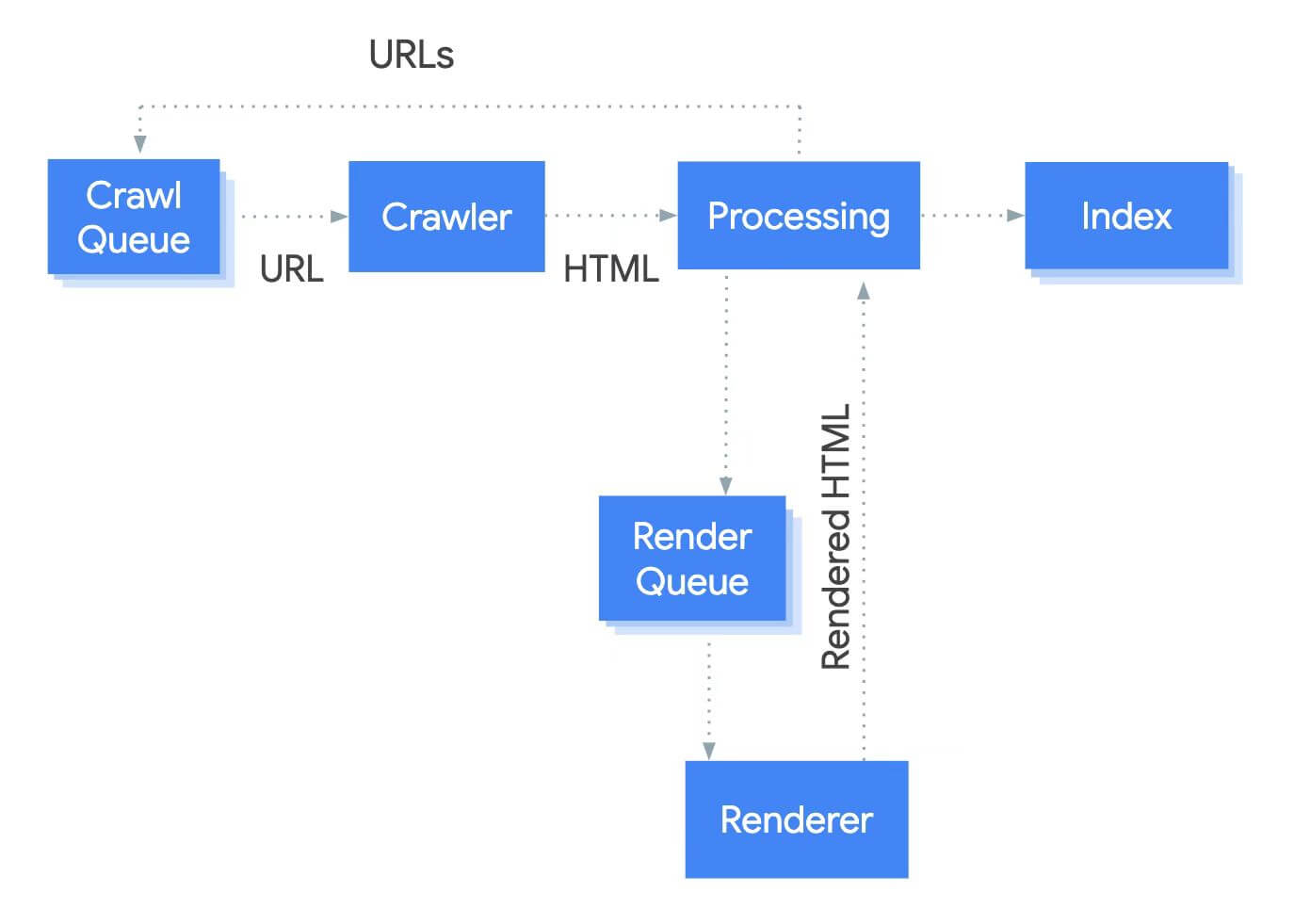
无论是 React、Vue 还是 Angular,SEO 问题的根源本质是“谷歌爬虫与浏览器的渲染差异”:谷歌bot虽能执行 JS,但存在 资源配额限制、渲染超时(例如之前再对JS支持较弱的时候仅 800ms 加载预算)、状态不持久, 三大枷锁,而 CSR 和 SSR 又会衍生出不同问题。
1. 客户端渲染(CSR)的共性坑点
CSR是框架默认的渲染方式,初始HTML仅一个空壳(如
1 | <div id="app"></div> |
),内容靠JS动态填充,但谷歌bot往往“等不及”或“加载不到”:
1.1渲染超时:异步数据加载(如React的useEffect 、Vue 的onMounted )若加载时间过长,爬虫会终止渲染,关键内容(如商品价格、文章正文)直接空白,会频繁遇到soft404,后续结果就是掉索引或者不收录,在遇到错误可以主动重定向到404页面或者替换Meta的Robots属性为noindex;
1.2资源黑洞:动态import() 、Web Worker资源、懒加载组件(如 React.lazy,Vue,defineAsyncComponent )可能被爬虫判定为“非必要资源”,直接跳过加载;
1.3 状态丢失:爬虫每次请求都会清空LocalStorage、SessionStorage和Cookie,依赖这些存储的内容(如用户偏好渲染的页面)会显示异常;
1.4 付费墙违规:部分站点用JS隐藏服务端返回的全量内容(如新闻正文),仅在验证订阅后显示——谷歌最新明确此方式“不可靠”,可能导致全量内容被收录,或未订阅内容被判定为“无效内容”。
2. 服务端渲染(SSR)的隐藏陷阱
SSR虽能预渲染HTML给爬虫,但配置不当反而会引发新问题:
2.1 hydration 不匹配:服务端渲染的 HTML 与客户端 JS 初始化后的 DOM 结构不一致(如时间格式化、动态类名),会触发浏览器重绘,爬虫可能抓取到“半成品”内容;
2.2 缓存冲突:谷歌bot缓存策略激进,若未用“内容指纹”(如 main.2bb85551.js ),可能加载旧版 JS/CSS,导致渲染异常;
2.3 资源超限:Angular Universal、Next.js 等 SSR 框架若打包后的 JS 超过 一定大小(移动端爬虫阈值),爬虫会直接终止执行。
三、React/Vue/Angular的SEO
不同框架的渲染机制略有差异,需针对性优化。以下方案均结合谷歌建议,兼顾“爬虫友好”与“开发效率”。
1. React避开useEffect 陷阱,用 Next.js 兜底
React 项目的核心 SEO 问题集中在 异步渲染延迟 和 客户端路由:
React CSR痛点:useEffect 中发起的请求(如获取文章列表),若响应时间超过 800ms,爬虫会错过内容;客户端路由用 hash (如 /#/article )时,谷歌已废弃 AJAX 抓取协议,无法识别路由。
解决方案:
- 优先用Next.js(React 官方推荐 SSR/SSG框架),通过 getServerSideProps (服务端实时渲染)或 getStaticProps (静态生成)预渲染内容,确保爬虫直接拿到完整 HTML:
1 |
|
客户端路由必须用 History API (Next.js 的Link 组件已默认实现),避免 hash 路由;
付费墙处理:仅在服务端验证订阅状态(如通过 Cookie 或请求头),未订阅用户返回“预览内容”+ 403 状态码,订阅用户才返回全量内容,避免 JS 隐藏全量内容。
2. Vue:警惕 v-if 渲染断层,Nuxt.js 是最优解
Vue项目的SEO坑多在条件渲染和懒加载组件:
Vue CSR痛点: v-if控制的关键内容(如商品描述)若依赖异步数据,爬虫可能因 JS 未执行看到空白; v-lazy懒加载的首屏图片,可能被爬虫判定为“非必要资源”。
解决方案:
- 用 Nuxt.js(Vue官方SSR框架),通过 asyncData或fetch在服务端获取数据,提前渲染v-if内容:
1 |
|
- 静态页面(如官网、博客)用“预渲染”替代 SSR:通过 prerender-spa-plugin 在打包时生成静态 HTML,无需服务器压力:
1 |
|
- 懒加载组件需加 noscript 降级:给爬虫提供静态内容,避免空白:
1 |
|
3. Angular:解决客户端路由盲区,Angular Universal 来救场
Angular 项目的 SEO 难点在 模块加载 和 状态管理:
Ng CSR痛点:Angular 的 RouterModule 若未配置 SSR,客户端路由切换时,爬虫无法识别新 URL 对应的内容;依赖NgRx状态的内容,可能因爬虫未执行 Action 导致空白。
解决方案:
- 集成 Angular Universal(Angular SSR 方案),通过 TransferState 传递服务端数据,避免客户端重复请求:
1 |
|
禁用客户端路由的 useHash选项,确保URL为正常路径(如 /article/1 );
付费墙需在 server.ts(Universal服务端入口)中验证订阅,未订阅用户返回 403并跳转预览页,避免客户端 JS 处理权限逻辑。
三、谷歌官方必做:6个JS SEO关键动作
无论用哪个框架,谷歌文档中明确的以下要求必须落地,否则优化效果会大打折扣:
用工具验证渲染结果:通过 Rich Results Test 或 Search Console URL 检查工具,模拟爬虫渲染,查看“渲染后的 DOM”是否包含关键内容,避免 JS 错误导致内容丢失;
杜绝 soft 404:SPA中页面不存在时,不能只返回200状态码+JS 跳转,需:
服务端返回 404 状态码,或客户端动态添加
1 | <mata name="robots" content="noindex"> |
(如Vue中: document.head.appendChild(metaRobots) );
内容指纹防缓存:JS/CSS 文件名加入哈希(如 main.2bb85551.js ),避免谷歌bot加载旧版资源;
处理用户权限请求:相机、麦克风等 API 需提供降级方案,如“未允许相机时显示静态图片”,谷歌bot不会授予权限;
HTTP fallback:不依赖 WebSockets、WebRTC 传递内容,需提供HTTP接口供爬虫获取数据;
付费墙合规:仅在订阅验证通过后(服务端验证)返回全量内容,禁止“服务端返回全量内容+JS 隐藏”,否则可能被谷歌判定为“内容误导”。
最后讨论下不同场景的JS SEO选型建议
高SEO需求,电商、新闻 :
SSR(Next.js/Nuxt/Universal) React/Vue/Angular
静态页面,官网、博客 :
预渲染(prerender-spa-plugin) React/Vue
快速迭代的轻量项目:
CSR + 动态meta(vue-meta/react-helmet)+ noscript(全框架适用)
付费墙内容:
服务端订阅验证 + 差异化内容返回(全部框架适用)
提醒:JS SEO 不是“一劳永逸”的工作,需定期用谷歌 Search Console 查看“抓取统计报告”,跟进谷歌对 JS 渲染的更新(如近期付费墙要求),才能持续保证收录效果。尤其是以后AI托管网站的介入,会更多基于JS的SEO场景需要研究。
参考引用:谷歌官方文档JavaScript付费墙