之前用PHP写了一个爬虫,结果图书馆不可以外网访问,就暂停了,最近加深了一下JS,,发现微信小程序用得是JS开发的前端,用得样式也是类似于CSS,可惜的是DOM不可以用了。看了两天API,就上手写了。
主要是用到了input组件和button组件其他的就是正则爬虫了。下面是demo截图


做之前也没了解过小程序上线要求是访问https的服务器,学校的外网没法访问,自己的服务器也没法访问,就没法上线了,自己用着体验版。(自娱自乐)
说一下思路,主要用到是wx.requset接口,去请求图书馆的服务器地址
POST也可以GET(大写)数据过去,然后正则匹配,输出到
下面具体:
在Page()里面写一个请求,把数据以JSON格式放到data函数里面,
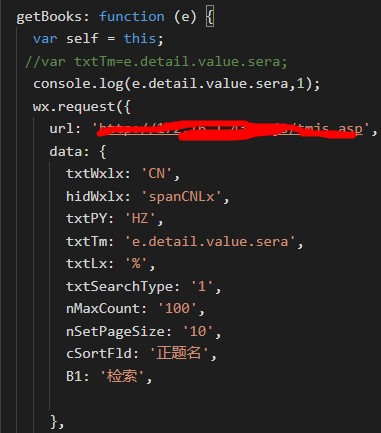
注意:header头部不可以自定义,只能用官方的两种,用下面这种会自动把数据编码发送。

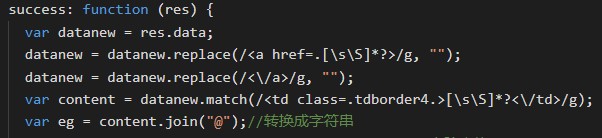
下面是success函数,请求成功返回res的data属性是数组或者JSON
下面匹配出查询的内容。
for (var i = 0; i < eg.length; i += 2) {//继续移到下一组第三个
eg.splice(i + 2, 3);//分割第三个开始,从eg删除三个元素
neweg = eg;//元素剩余47个
//neweg.push(tmp);
// console.log(neweg);
}
// self.setData({
// ag: neweg
上面写了一个循环,因为每个图书有很多属性,只需要其中的编号和数书名,需要每隔固定的长度输出需要的,学校图书馆的书本属性是5个,用到第一个和第二个。
下面说说wxml写法:由于不支持table标签,用得是弹性盒子flex属性
html
<view class='container-bottom'>
<view class='colums'>
<view class='row' wx:for="{{ag}}" >
<view class='colum' wx:if="{{index%2==0}}" >图书编号:{{item}}</view>
<view class='colum' wx:else >书籍名称:{{item}}</view>
</view>
</view>
这里双重括号是用来绑定page里面的数据的。小程序用json,js,wxml,wxcss,分别来实现配置,交互,视图,样式
样式和html部分不一致,具体,官方看看吧。
记录一下,过程,学下小程序的API,挺神奇的,封装了很多组件和接口,很方便,就是上线要求高。
感觉还是要把JS学好,加油吧。

